Product Promotion
gittech.site
for different kinds of informations and explorations.
xmllm – Structured LLM streaming output using lenient XML parsing
xmllm
xmllm is a JS utility that makes it easy to get structured data from LLMs, using a boring, time-tested, semantically enriched human-writable/readable syntax that is resilient and forgiving of human-made (and thus, LLM-made) mistakes.
PLEASE: This is very experimental. I have shipped fully operable apps with xmllm but please have patience whenever trying to derive structured data from LLMs. It's not as deterministic as normal programming. You can find demos and examples in the xmllm_demos repo. Shipped live at xmllm.j11y.io if you want to have a play (rate-limited so apologies for any issues!)
I'm looking for collaborators and testers to help me improve this library.
Simple example:
import { simple } from 'xmllm';
await simple('fun pet names', {
schema: { name: Array(String) }
}); // => ["Daisy", "Whiskers", "Rocky"]
What actually happened:
┌───────────────────┐ ┌─────────────────────────┐ ┌─────────────────────────┐
│ │ │ LLM generates │ │ XML parsed to │
│ "fun pet names" │ ──▶ │ <name>Daisy</name> │ ──▶ │ structured data via │
│ │ │ <name>Whiskers</name> │ │ schema {name: [String]} │
│ │ │ <name>Rocky</name> │ │ │
└───────────────────┘ └─────────────────────────┘ └─────────────────────────┘
Prompt sent to LLM LLM's natural output Final result:
["Daisy", "Whiskers", "Rocky"]
Even messy XML is recoverable!
Because xmllm uses a rather flexible HTML parser, even LLMs providing weird flourishes or non-contiguous XML will still be able to be parsed, e.g.
Hi im a plucky and annoying
little llm and sure i can
help with your request for
PET NAMES, how about <name>
Charlie</name> or
maybe <name>Bella </ IM MESSING THINGS UP ></name>
<name>King
Julian
... from which we can still recover:
{
name: ['Charlie', 'Bella', 'King Julian']
}
XML {through the eyes of a forgiving HTML parser.}
Why XML? – XML allows LLMs to communicate naturally with the best merits of 'free prose' while still giving you structured data back. In contrast, the norm of deriving JSON from LLMs via 'Function Calling' or 'Tool Use' is famously brittle. And (anecdotally) these approaches are biased to more "robotic" transactional completions, arguably lacking some of the more fluid or creative higher-temperature completions we have come to value from language models. And they make streaming a headache. Markup languages like XML, however, excel at these things.
Here's an example of a UI being progressively populated by a streaming LLM 'alien species' generator:
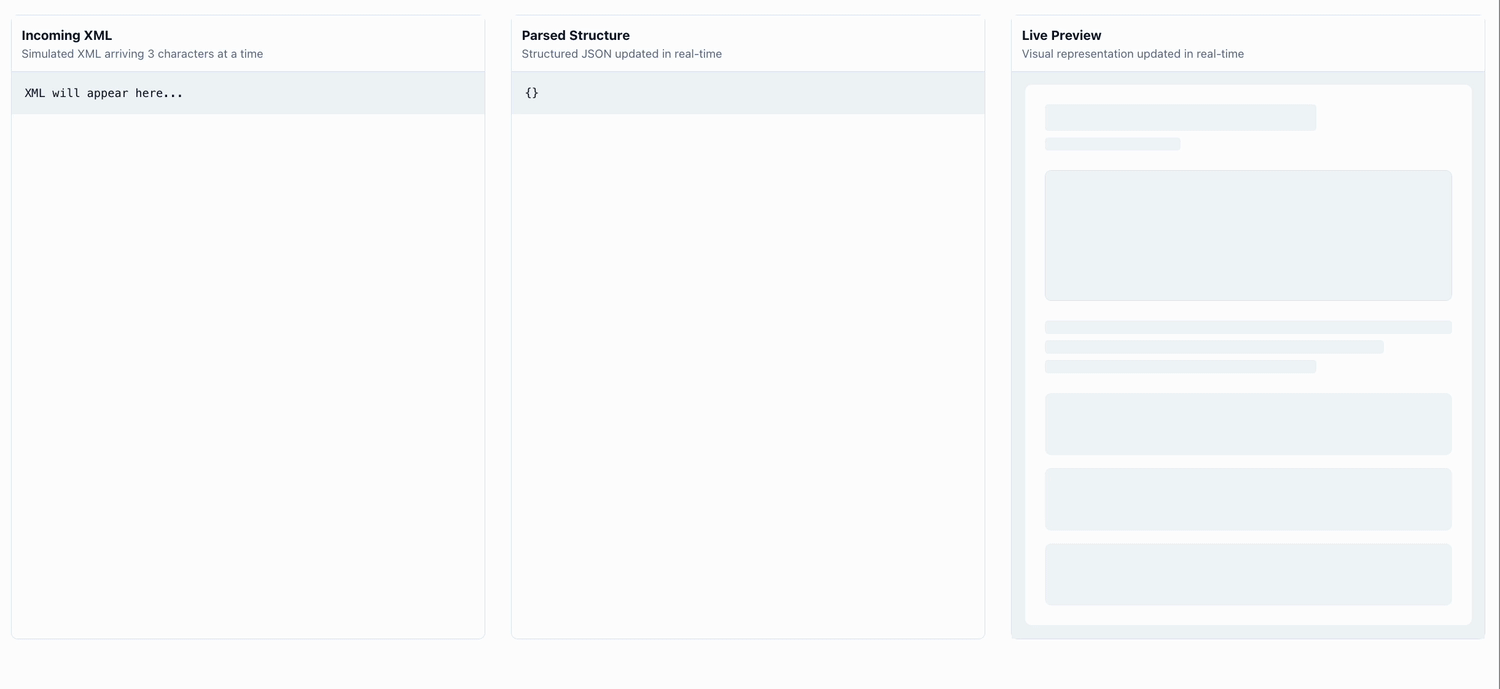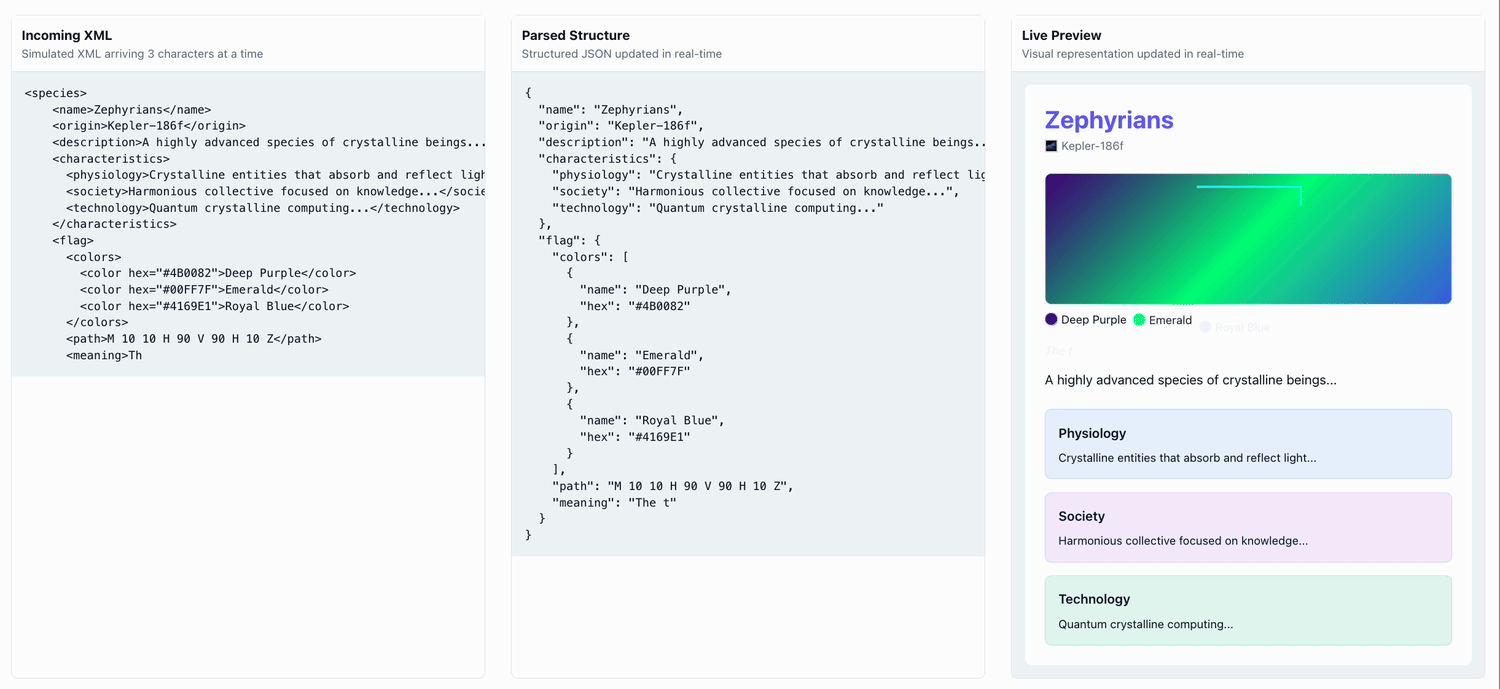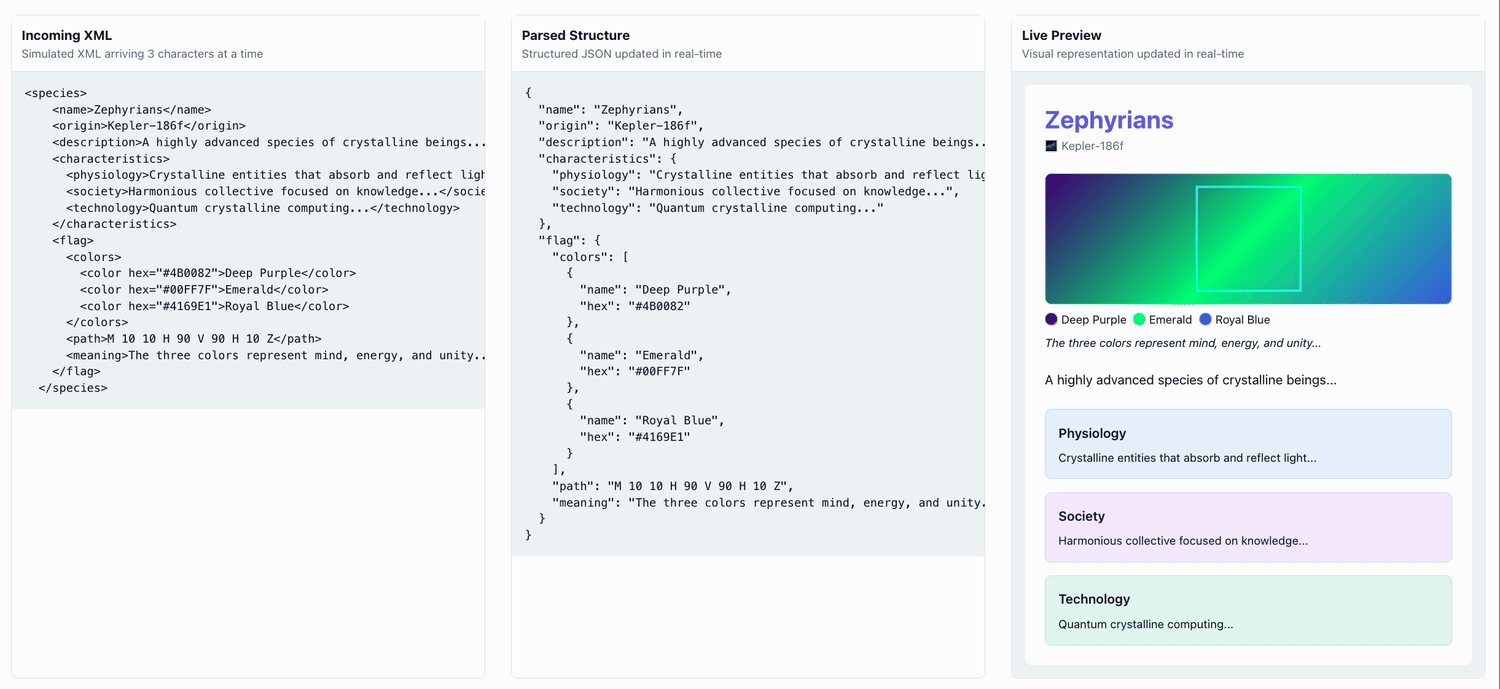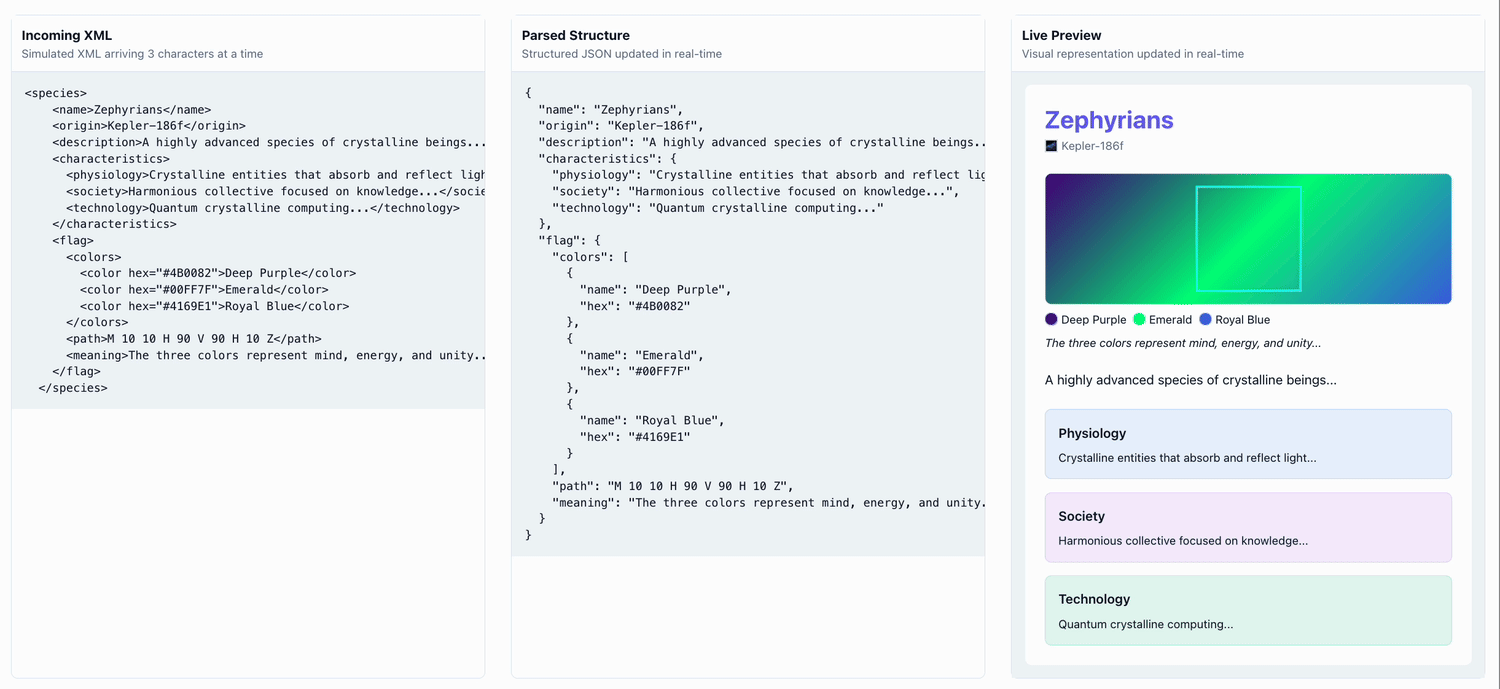
Demo Repo
Fork and play with the xmllm demos repo, or:
🔥 See it live here: xmllm.j11y.io
Provider-agnostic & high compliance on many models!
xmllm is able to be run against most conceivable endpoints since you can define custom providers. We define some providers out of the box like anthropic, openai, openrouter, togetherai, perplexityai. You will usually put the API keys in a .env file but you can also put them inline. Additionally, if you're worried about rate limits or random failures, you can define fallback models.
stream('fun pet names', {
schema: {
name: Array(String)
},
// If I am super cautious about network or LLM provider stability,
// I can define fallback models:
model: [
// Preferred model:
'openrouter:mistralai/ministral-3b',
// Fallback models:
'anthropic:claude-3-haiku-20240307',
'togetherai:Qwen/Qwen2.5-7B-Instruct-Turbo',
// Super-custom fallback model:
{
inherit: 'openai', // indicating open-ai endpoint compatibility
endpoint: 'https://api.myCustomLLM.com/v1/chat/completions',
key: 'sk-...'
}
]
});
In addition to the big frontier models, xmllm has impressive schema compliance on mid-to-low-param models like: Llama 3.1 8B, Qwen2.5-7B-Instruct-Turbo, Nous Hermes 2 Mixtral, Qwen 2.5 Coder 32B. And, where lacking, compliance can usually be improved by using hints in addition to schemas and a bit of experimental prompt-engineering.
Famous strawberry problem
Here's an example with a slightly more complex schema, which in this case let's us enforce some kind of structured chain-of-thought and the containment of a 'final answer':
import { simple } from 'xmllm';
const analysis = await simple(
`
How many Rs are in the word strawberry?
Count the letters prior to your answer.
`,
{
approach: 'the approach you will use for counting',
letter: [{
character: String,
is_r_letter: Boolean
}],
final_answer: String
},
{
model: 'openrouter:mistralai/ministral-3b',
max_tokens: 1000
}
);
The LLM responds naturally with XML:
<approach>To solve this problem, I will count the number of R/r letters
in the word 'strawberry'.</approach>
<letter>
<character>s</character>
<is_r_letter>false</is_r_letter>
</letter>
<letter>
<character>t</character>
<is_r_letter>false</is_r_letter>
</letter>
<letter>
<character>r</character>
<is_r_letter>true</is_r_letter>
</letter>
<!-- ... more letters ... -->
<final_answer>There are 3 Rs in the word 'strawberry'.</final_answer>
Which transforms into structured data:
{
approach: "To solve this problem, I will first count...",
letter: [
{"character": "s", "is_r_letter": false},
{"character": "t", "is_r_letter": false},
{"character": "r", "is_r_letter": true},
//....
],
final_answer: "There are 3 Rs in the word 'strawberry'."
}
➠ Model Compliance Dashboard
View the Model Compliance Matrix to see how well xmllm works with different models and prompting strategies.
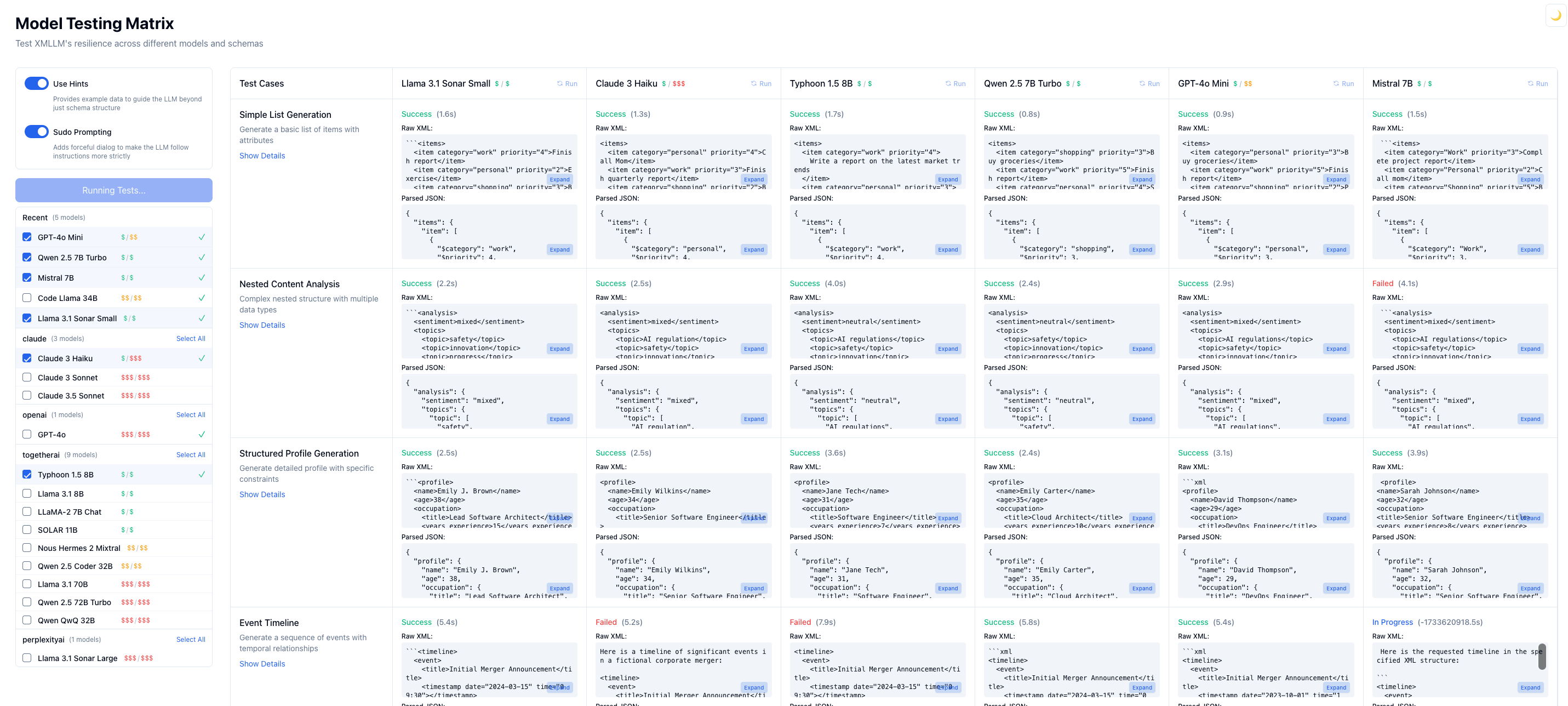
How does it work?
TLDR: Schema-guided prompt→Stream XML→HTML parser→Data
Under the hood, xmllm uses different prompting strategies, pairing custom system prompts and custom user/assistant pairings. These prompts tell the LLM the structure of the XML it must output using your provided schemas (and optional hints). This prompting method has been tested with a variety of models, including low param models like Ministral-3B and Qwen2.5-7B. Once the stream starts coming in, xmllm uses a lenient streaming HTML parser (htmlparser2) to extract the data then reflect it back to you in the structure of your schema. This data can be reflected in real time or you can wait until the stream completes and then get the final value.
Resilience & Errors:
LLMs are usually quite flakey and unstructured in what output they give you, despite our best efforts to constrain. Therefore xmllm follows the latter of Postel's Law: "Be liberal in what you accept". The HTML parser will be flexible in what it accepts and so even if the XML is messy or non-contiguous, xmllm will still give you back what it finds.
Quick Start
# Install
npm install xmllm
# Set up environment variables
# Create a .env file:
ANTHROPIC_API_KEY=your_api_key
OPENAI_API_KEY=your_api_key
TOGETHERAI_API_KEY=your_api_key
PERPLEXITYAI_API_KEY=your_api_key
Simplest Usage
The simple() function provides the easiest way to get structured data from AI.
import { simple } from 'xmllm';
// Updated usage with options object
const result = await simple("What is 2+2?", {
schema: { answer: Number },
model: {
inherit: 'anthropic',
name: 'claude-3-haiku-20240307',
key: process.env.ANTHROPIC_API_KEY
}
});
console.log(result);
// { answer: 4 }
Streaming Usage
The stream() API offers a simple interface for streaming with or without a schema. Some examples:
import { stream } from 'xmllm';
// 1. NO SCHEMA: Use CSS selectors to manually extract things:
const thoughts = stream(`
Share three deep thoughts about programming. Use a structure like:
<thought>...</thought>
<thought>...</thought> etc.
`)
.select('thought') // Select <thought> elements
.text(); // Extract text content
for await (const thought of thoughts) {
console.log('AI is thinking:', thought); // See thoughts as they arrive
}
// 2. WITH A SCHEMA: Structured Data:
const result = await stream('What is 2+2?', {
schema: {
answer: {
value: Number,
explanation: String
}
}
}).last(); // wait until the stream completes
Here's a more qualified example of the earlier color scenario where we're:
- Defining a schema to increase compliance (i.e. more likely to get XML from the LLM)
- Using
closedOnly()prior toselect()to ensure we'll only get tags when they're closed. - Configuring a custom model and provider (in this case, inheriting from the togetherai-style payloader).
const colors = [];
for await (
const {color} of
stream('List colors as <color>...</color>', {
model: {
inherit: 'togetherai',
name: 'Qwen/Qwen2.5-7B-Instruct-Turbo',
endpoint: 'https://api.together.xyz/v1/chat/completions',
key: process.env.TOGETHERAI_API_KEY
},
schema: {
color: Array(String)
}
}).closedOnly() // ensure tags are closed
) {
colors.push(...color); // Add new colors to array
console.log('Current colors:', colors);
}
See more details in the Streaming Guide.
Schemas!
xmllm uses schemas to transform XML into structured data.
const schema = {
analysis: {
score: Number,
tag: [String],
details: {
$lang: String, // Attribute
$text: String // Text content
}
}
};
A schema is an object that indicates what kind of object you want back from xmllm at the end of the process. So if you want an array of strings under the key 'color' you'll use:
{ color: Array(String) }
This will give you something like:
{ color: ['red', 'blue', 'green'] }
You vital thing when composing schemas with xmllm is to realize that each key you define becomes an XML element. So, we are using the key 'color' instead of 'colors' because we want this:
<color>red</color>
<color>blue</color>
<color>green</color>
And NOT:
<colors>red</colors>
<colors>blue</colors>
<colors>green</colors>
And as such the key on the returned data will be color, not colors.
The best practice to avoid this mental overhead is to wrap a singular named array in a plurally named container, like this:
schema = {
colors: {
color: Array(String)
}
}
... which would get you:
<colors>
<color>red</color>
<color>blue</color>
<color>green</color>
</colors>
This makes things simpler usually.
This plural/singular thing is, tbh, a leaky abstraction. But if you're savvy enough to be dealing with the leakiest and most chaotic abstractions ever -- LLMs -- then hopefully you're not dissuaded.
See more details in the Schema Guide.
Provider-Agnostic / Max-configuration
xmllm supports multiple AI providers. You'll need at least one:
| Provider | Key | Models such as... |
|---|---|---|
Anthropic (anthropic) | ANTHROPIC_API_KEY | Claude Sonnet, Haiku, Opus |
OpenAI (openai) | OPENAI_API_KEY | GPT-4o, GPT-4o-mini |
Together.ai (togetherai) | TOGETHERAI_API_KEY | Qwen, Mistral, Llama, etc. |
Perplexity (perplexityai) | PERPLEXITYAI_API_KEY | Llama, Mistral, etc. |
OpenRouter (openrouter) | OPENROUTER_API_KEY | Everything! |
See many more details in the Provider Setup guide.
// Configure at runtime or in an `.env` file
stream('My prompt goes here', {
keys: { openrouter: process.env.OPENROUTER_API_KEY },
model: 'openrouter:mistralai/ministral-3b'
})
Browser Usage
For browser environments, use the client interface with a proxy server so that your LLM API keys stay private. This is most useful for development and experimentation. Production apps should tbh keep all direct LLM interfacing on the server.
import { stream, ClientProvider } from 'xmllm/client';
const client = new ClientProvider('http://localhost:3124/api/stream');
const result = await stream('Tell me a joke', {
schema: { joke: String }
}, client).last()
// btw: last() is a shortcut for getting the very final value
// i.e. the completed stream
Lower-level Pipeline API
xmllm provides a lower-level pipeline API for complex scenarios where you might want several stream-friendly transformations or generations to happen in a row.
Contrived example:
import { pipeline } from 'xmllm';
let results = {};
const analysis = pipeline(({ prompt, promptClosed }) => [
// First prompt gets a scientist
// promptClosed means 'close the tags before yielding'
promptClosed('Name a scientist', {
scientist: {
name: String,
field: String
}
}),
// Then we get a discovery in a distinct LLM inference
promptClosed((incoming) => {
results.scientist = incoming.scientist;
return {
messages: [{
role: 'user',
content: `What was ${incoming.scientist.name}'s biggest discovery?`,
}],
schema: {
discovery: {
year: Number,
description: String
}
}
};
}),
// Combine results
({discovery}) => {
// (we would have already stored scientist btw)
results.discovery = discovery;
return results;
}
]);
await analysis.last();
// {
// "scientist": {
// "name": "Albert Einstein",
// "field": "Theory of Relativity"
// },
// "discovery": {
// "year": 1905,
// "description": "E=mc², the theory of relativity"
// }
// }
See the Pipeline Guide for more advanced usage like parallel processing, complex transformations, and error handling.
In-Depth Documentation
- Schema Guide
- Provider Setup
- Stream Interface
- Streaming with a Schema
- Raw Streaming
- Prompt Strategies
- Advanced Pipeline Guide
- Complete API Reference
Installing
npm install xmllm
# or
pnpm add xmllm
# or
yarn add xmllm
Importing
xmllm supports both ESM and CommonJS imports:
// ESM (recommended)
import { simple, stream } from 'xmllm';
// CommonJS
const { simple, stream } = require('xmllm');
// Alternative CommonJS if you have issues
const xmllm = require('xmllm');
const { simple, stream } = xmllm;
License
MIT
Made with ❤️
to provide different kinds of informations and resources.